Time - Memory Tradeoff With the Example of Java Maps
Join the DZone community and get the full member experience.
Join For Freethis article illustrates the general time - memory tradeoff with the example of different hash table implementations in java. the more memory a hash table takes, the faster each operation (e. g. getting a value by key or putting an entry) is performed.
benchmarking method
hash maps with
int
keys and
int
values were tested. memory measure is relative usage over theoretical minimum. for example, 1000 entries of int key and value take at least (4 (size of int) + 4) * 1000 = 8000 bytes. if the hash map implementation takes 20 000 bytes, it's memory overuse is (20 000 - 8000) / 8000 = 1.5. each implementation was benchmarked on 9 different load levels (load factors). on each load level, each map was filled with 10 numbers of entries, logariphmically evenly distributed bewteen 1000 and 10 000 000 (to study caching effects). then, for the same implementation and load level, memory metrics and average operation throughputs are averaged independently, over 3 smallest sizes (small sizes), 3 largest sizes (large sizes) and all 10 sizes from 1000 to 10 000 000 (all sizes). implementations:
- higher frequency trading collections (hftc)
- high performance primitive collections (hppc)
- fastutil collections
- goldman sachs collections (gs)
- trove collections
- mahout collections
-
java.util.hashmapas a reference
get value by key (successful)
only looking at these charts, you can suppose that hftc, trove and mahout on the one size, fastutil, hppc and gs on the another use the same hash table algorithm. (in fact, it is not quite true.) sparser hash table on average performs less lookups during key search, therefore less memory reads, therefore the operation finishes earlier. notice, that on small sizes the largest maps are the fastest for all implementations, but on large and all sizes there isn't visible progress starting from memory overuse ~4. that's because when the total memory taken by the map goes beyond cpu cache capacity, cache misses become more often when the map is getting larger. this effect compensates algorithic trend.
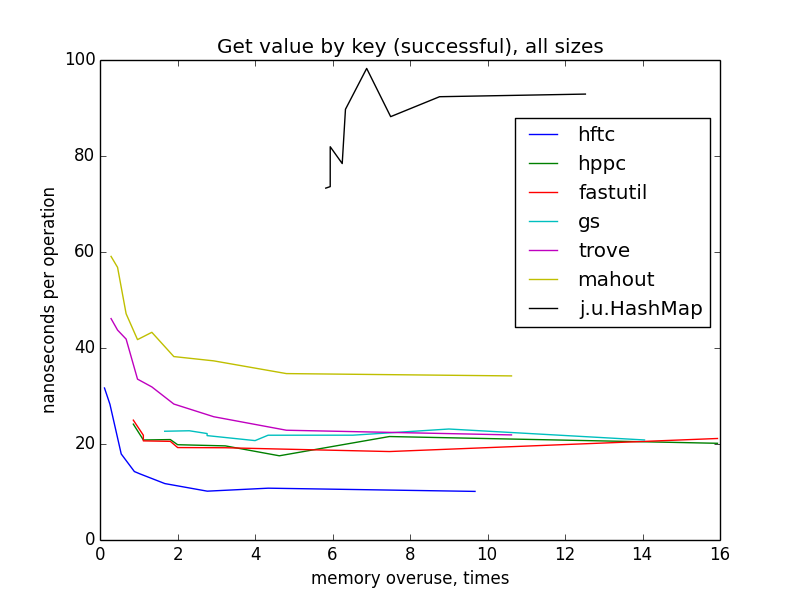
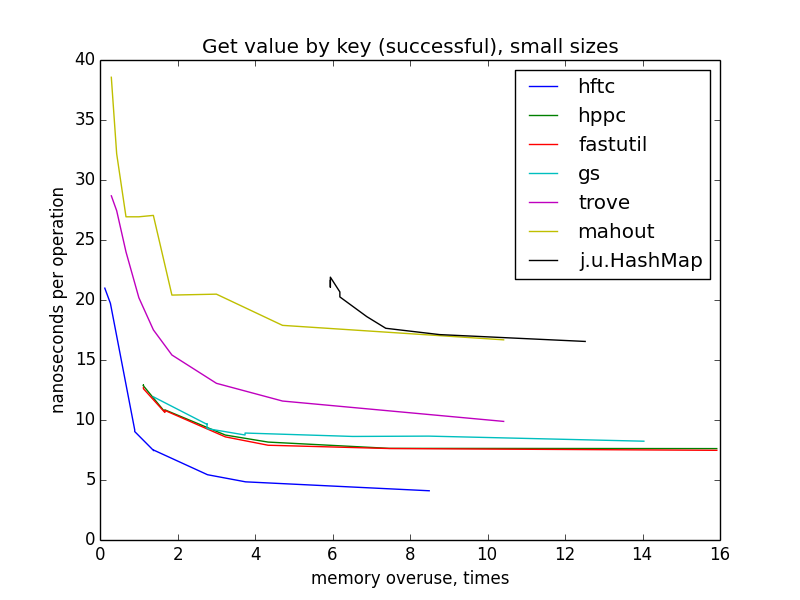
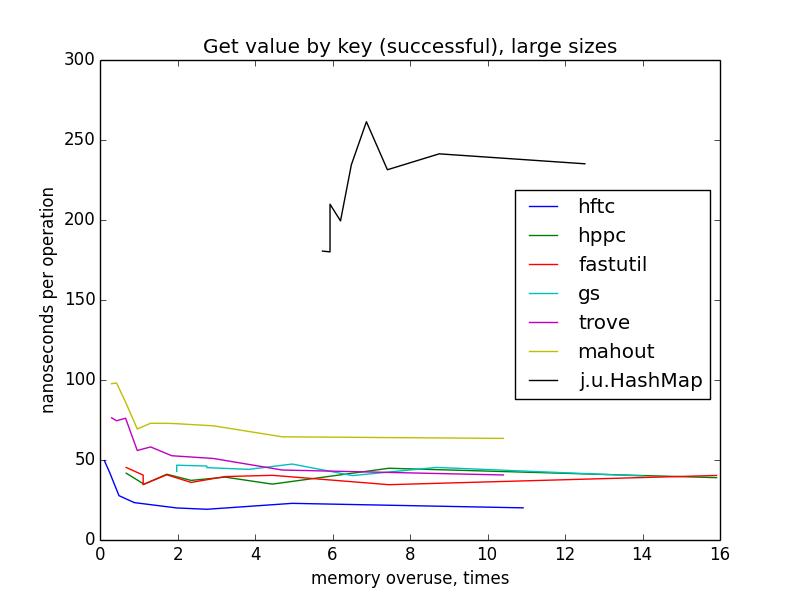
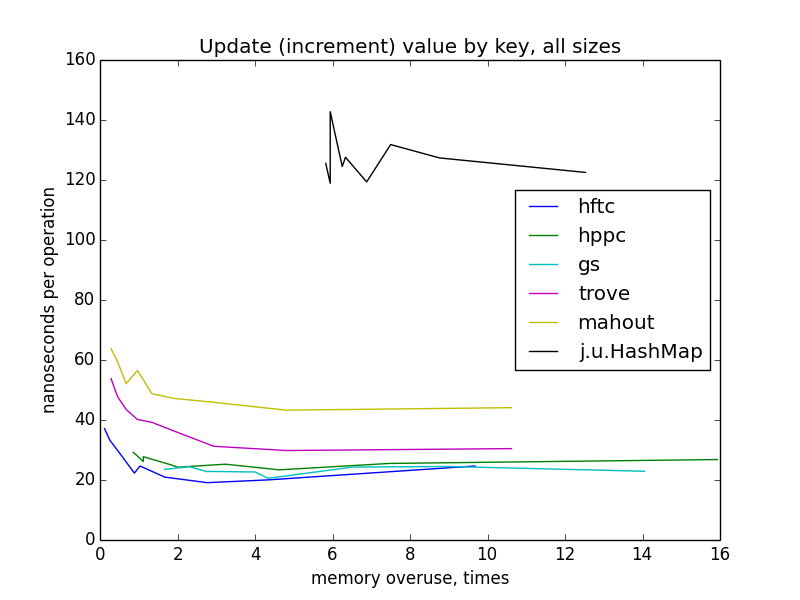
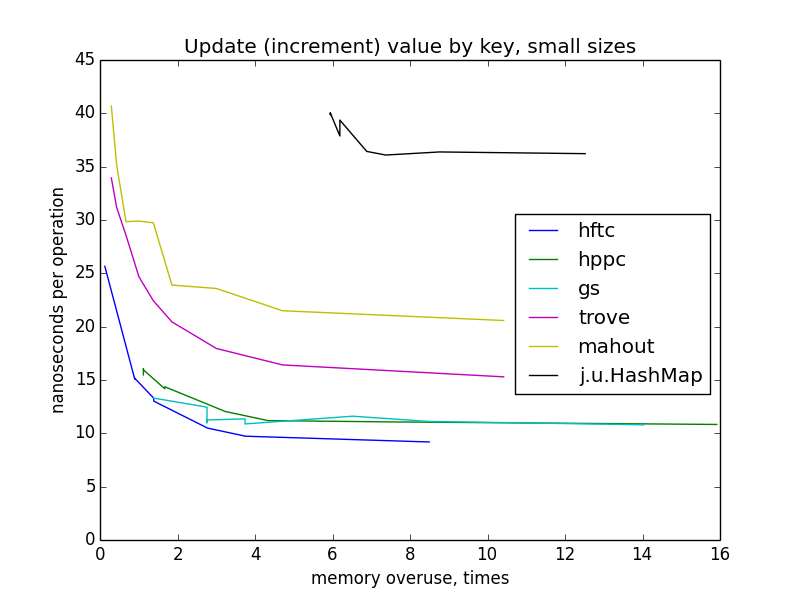
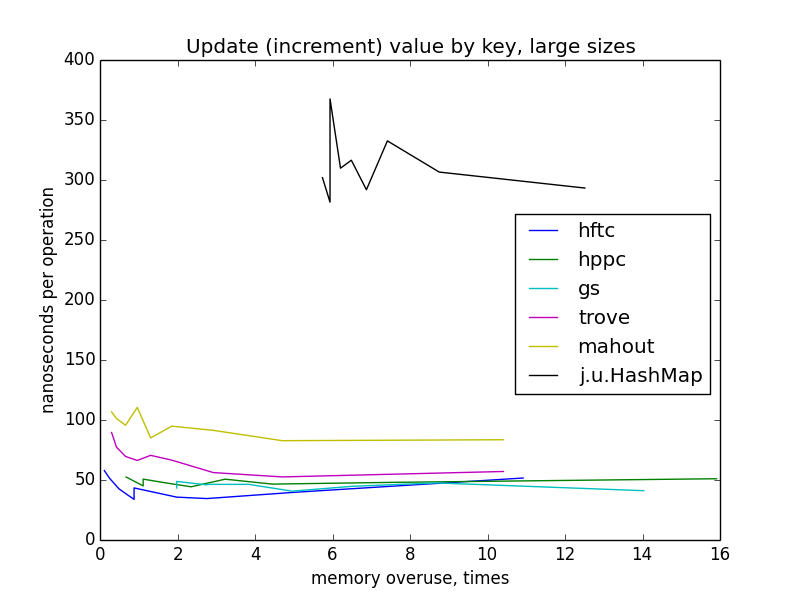
update (increment) value by key
update operation behaves pretty similar to get(). fastutil wasn't benchmarked, because there aren't fairly performant method for this task in it's api.
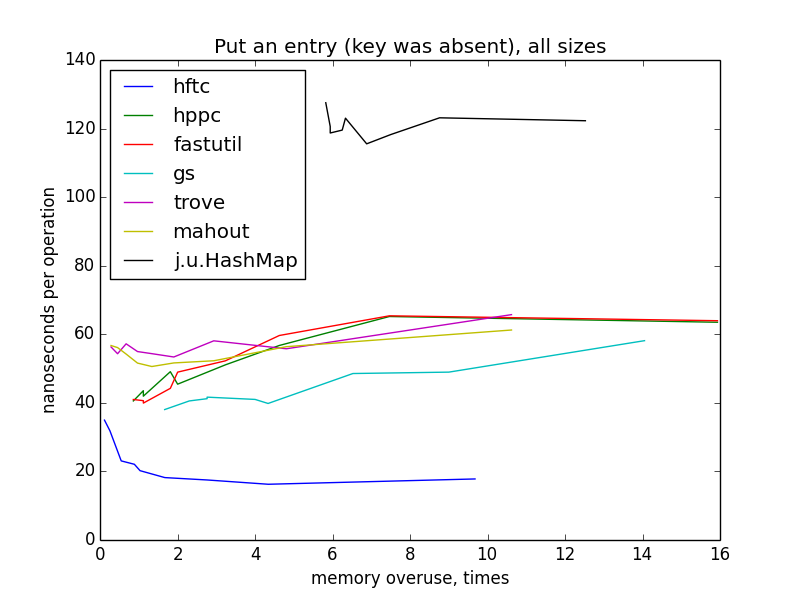
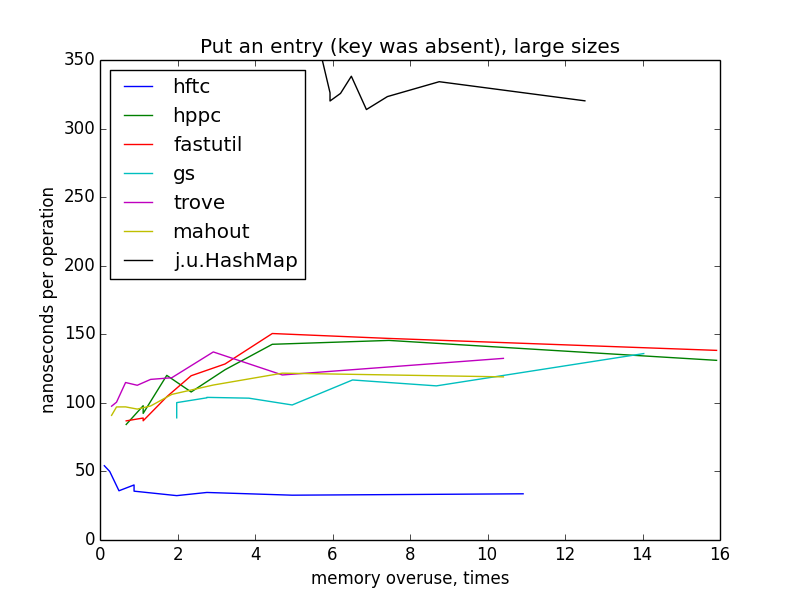
put an entry (key was absent)
in this case, maps were gradually filled in with the entries from the size 0 to the target size (1000 - 10 000 000). rehash shouldn't occur, because maps were constructed with the target size provided. for small sizes, plots still looks like hyperbolas, but i can't explain so dramatic change on large sizes and differences between hftc and other primitive implementations.

internal iteration (foreach)
iteration is getting slower with memory usage growth. interesting thing about external iteration: for all open hash table implementations throughtput depends
only
memory usage, not even on load factor (which differs for implementations for the same memory usage). also, foreach throughput don't depend on open hash table size.
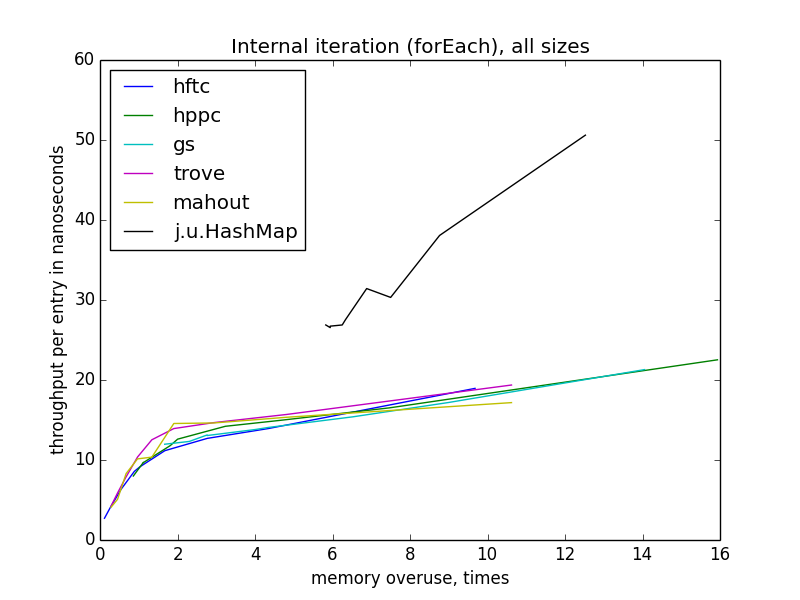
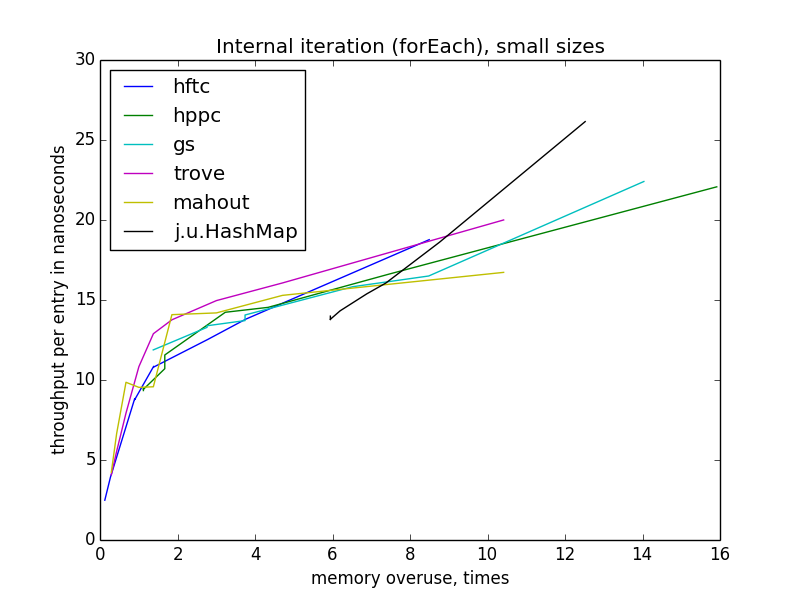
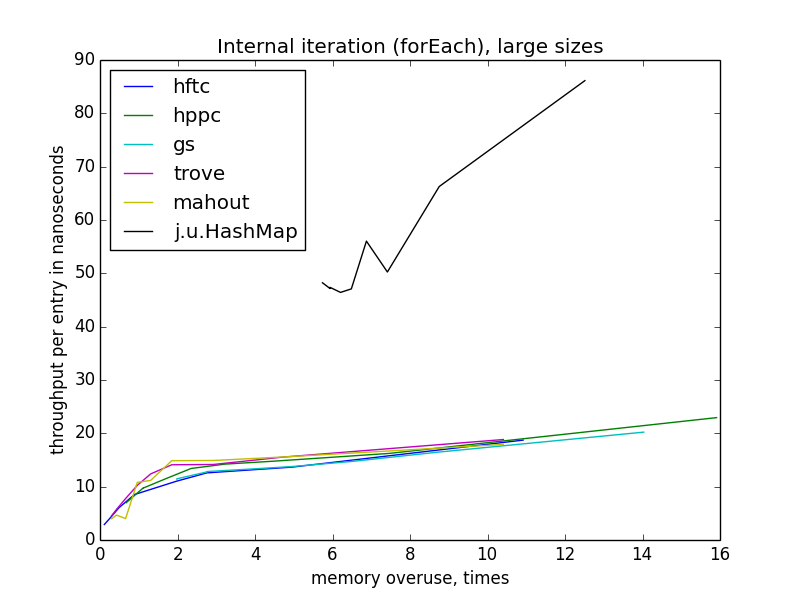
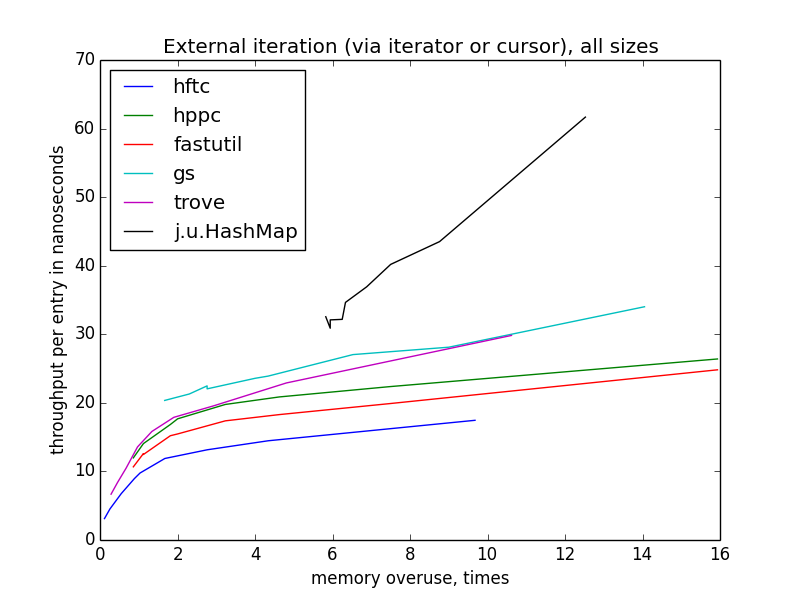
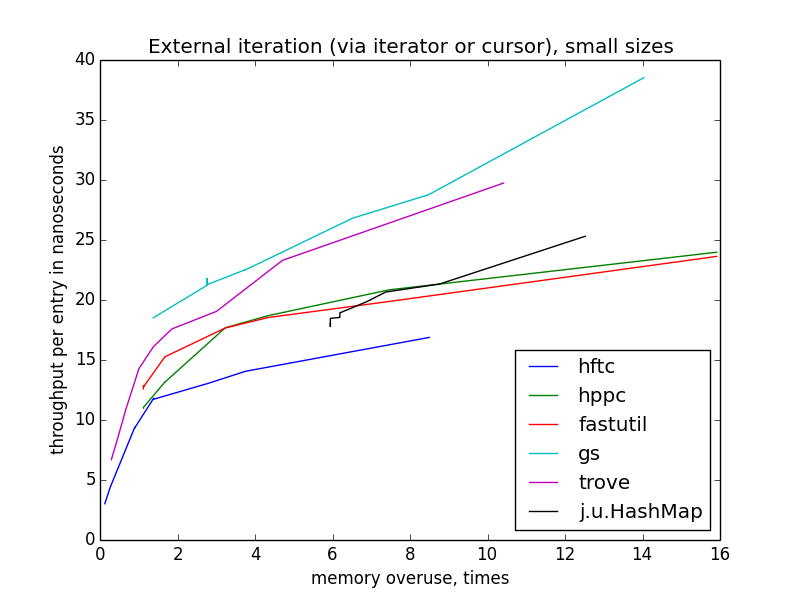
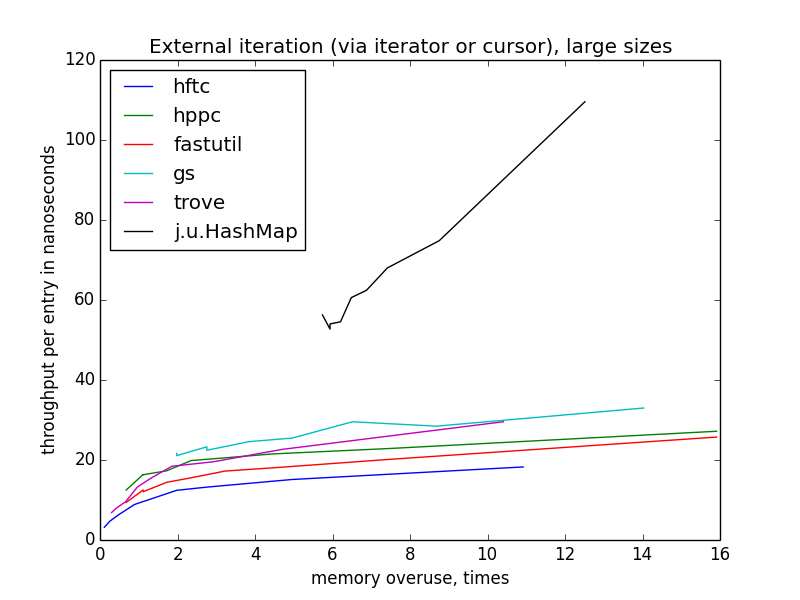
external iteration (via iterator or cursor)
external iteration performance is more varying than internal, because there is more freedom for optimization. hftc and trove employ own iteration interfaces, other libraries use standard
java.util.iterator
.
footnote
raw benchmark results from which the pictures were built with a link to the benchmarking code and information about the runsite in description.
Opinions expressed by DZone contributors are their own.
Comments