Streaming Big Data: Storm, Spark and Samza
Join the DZone community and get the full member experience.
Join For FreeThere are a number of distributed computation systems that can process Big Data in real time or near-real time. This article will start with a short description of three Apache frameworks, and attempt to provide a quick, high-level overview of some of their similarities and differences.
Apache Storm
In Storm, you design a graph of real-time computation called a topology, and feed it to the cluster where the master node will distribute the code among worker nodes to execute it. In a topology, data is passed around between spouts that emit data streams as immutable sets of key-value pairs called tuples, and bolts that transform those streams (count, filter etc.). Bolts themselves can optionally emit data to other bolts down the processing pipeline.

Apache Spark
Spark Streaming (an extension of the core Spark API) doesn’t process streams one at a time like Storm. Instead, it slices them in small batches of time intervals before processing them. The Spark abstraction for a continuous stream of data is called a DStream (for Discretized Stream). A DStream is a micro-batch of RDDs (Resilient Distributed Datasets). RDDs are distributed collections that can be operated in parallel by arbitrary functions and by transformations over a sliding window of data (windowed computations).

Apache Samza
Samza ’s approach to streaming is to process messages as they are received, one at a time. Samza’s stream primitive is not a tuple or a Dstream, but a message. Streams are divided into partitions and each partition is an ordered sequence of read-only messages with each message having a unique ID (offset). The system also supports batching, i.e. consuming several messages from the same stream partition in sequence. Samza`s Execution & Streaming modules are both pluggable, although Samza typically relies on Hadoop’s YARN (Yet Another Resource Negotiator) and Apache Kafka.

Common Ground
All three real-time computation systems are open-source, low-latency, distributed, scalable and fault-tolerant. They all allow you to run your stream processing code through parallel tasks distributed across a cluster of computing machines with fail-over capabilities. They also provide simple APIs to abstract the complexity of the underlying implementations.
The three frameworks use different vocabularies for similar concepts:

Comparison Matrix
A few of the differences are summarized in the table below:

There are three general categories of delivery patterns:
- At-most-once: messages may be lost. This is usually the least desirable outcome.
- At-least-once: messages may be redelivered (no loss, but duplicates). This is good enough for many use cases.
- Exactly-once: each message is delivered once and only once (no loss, no duplicates). This is a desirable feature although difficult to guarantee in all cases.
Another aspect is state management. There are different strategies to store state. Spark Streaming writes data into the distributed file system (e.g. HDFS). Samza uses an embedded key-value store. With Storm, you’ll have to either roll your own state management at your application layer, or use a higher-level abstraction called Trident.
Use Cases
All three frameworks are particularly well-suited to efficiently process continuous, massive amounts of real-time data. So which one to use? There are no hard rules, at most a few general guidelines.
If you want a high-speed event processing system that allows for incremental computations, Storm would be fine for that. If you further need to run distributed computations on demand, while the client is waiting synchronously for the results, you’ll have Distributed RPC (DRPC) out-of-the-box. Last but not least, because Storm uses Apache Thrift, you can write topologies in any programming language. If you need state persistence and/or exactly-once delivery though, you should look at the higher-level Trident API, which also offers micro-batching.
A few companies using Storm: Twitter, Yahoo!, Spotify, The Weather Channel...
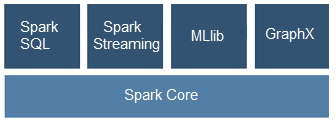
Speaking of micro-batching, if you must have stateful computations, exactly-once delivery and don’t mind a higher latency, you could consider Spark Streaming…specially if you also plan for graph operations, machine learning or SQL access. The Apache Spark stack lets you combine several libraries with streaming (Spark SQL, MLlib, GraphX) and provides a convenient unifying programming model. In particular, streaming algorithms (e.g. streaming k-means) allow Spark to facilitate decisions in real-time.
A few companies using Spark: Amazon, Yahoo!, NASA JPL, eBay Inc., Baidu…
If you have a large amount of state to work with (e.g. many gigabytes per partition), Samza co-locates storage and processing on the same machines, allowing to work efficiently with state that won’t fit in memory. The framework also offers flexibility with its pluggable API: its default execution, messaging and storage engines can each be replaced with your choice of alternatives. Moreover, if you have a number of data processing stages from different teams with different codebases, Samza ‘s fine-grained jobs would be particularly well-suited, since they can be added/removed with minimal ripple effects.
A few companies using Samza: LinkedIn, Intuit, Metamarkets, Quantiply, Fortscale…
Conclusion
We only scratched the surface of The Three Apaches. We didn’t cover a number of other features and more subtle differences between these frameworks. Also, it’s important to keep in mind the limits of the above comparisons, as these systems are constantly evolving.
Published at DZone with permission of Tony Siciliani, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments