Modeling Data in Neo4j: Bidirectional Relationships
Join the DZone community and get the full member experience.
Join For Freetransitioning from the relational world to the beautiful world of graphs requires a shift in thinking about data. although graphs are often much more intuitive than tables, there are certain mistakes people tend to make when modelling their data as a graph for the first time. in this article, we look at one common source of confusion: bidirectional relationships.
directed relationships
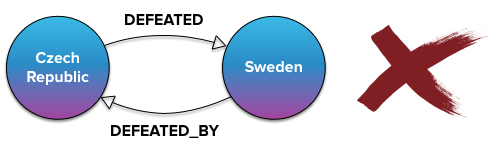
relationships in neo4j must have a type, giving the relationship a semantic meaning, and a direction. frequently, the direction becomes part of the relationship's meaning. in other words, the relationship would be ambiguous without it. for example, the following graph shows that the czech republic defeated sweden in ice hockey. had the direction of the relationship been reversed, the swedes would be much happier. with no direction at all, the relationship would be ambiguous, since it would not be clear who the winner was.

note that the existence of this relationship implies a relationship of a different type going in the opposite direction, as the next graph illustrates. this is often the case. to give another example, the fact that pulp fiction was directed_by quentin tarantino implies that quentin tarantino is_director_of pulp fiction. you could come up with a huge number of such relationship pairs.
one common mistake people often make when modelling their domain in neo4j is creating both types of relationships. since one relationship implies the other, this is wasteful, both in terms of space and traversal time. neo4j can traverse relationships in both directions. more importantly, thanks to the way neo4j organizes its data, the speed of traversal does not depend on the direction of the relationships being traversed.
bidirectional relationships
some relationships, on the other hand, are naturally bidirectional. a classic example is facebook or real-life friendship. this relationship is mutual - when someone is your friend, you are (hopefully) his friend, too. depending on how we look at the model, we could also say such relationship is undirected.
graphaware and neo technology are partner companies. since this is a mutual relationship, we could model it as bidirectional or undirected relationship, respectively.
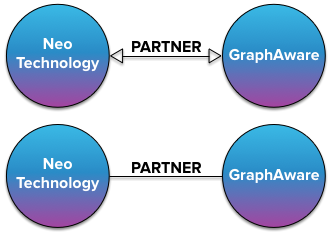
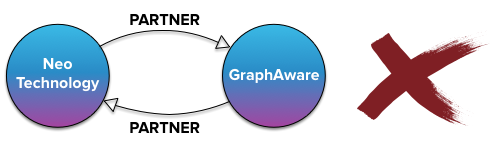
but since none of this is directly possible in neo4j, beginners often resort to the following model, which suffers from the exact same problem as the incorrect ice hockey model: an extra unnecessary relationship.
neo4j apis allow developers to completely ignore relationship direction when querying the graph, if they so desire. for example, in neo4j's own query language, cypher, the key part of a query finding all partner companies of neo technology would look something like
match (neo)-[:partner]-(partner)
the result would be the same as executing and merging the results of the following two different queries:
match (neo)-[:partner]->(partner)and
match (neo)<-[:partner]-(partner)
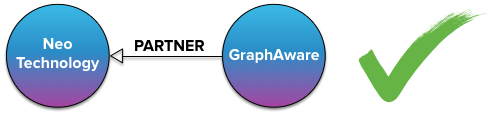
therefore, the correct (or at least most efficient) way of modelling the partner relationships is using a single partner relationship with an arbitrary direction .
conclusion
relationships in neo4j can be traversed in both directions with the same speed. moreover, direction can be completely ignored. therefore, there is no need to create two different relationships between nodes, if one implies the other.
Opinions expressed by DZone contributors are their own.
Comments